la bioinformatique dans un projet de recherche
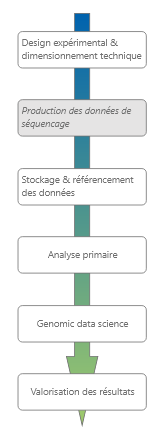
Le besoin en compétences bioinformatiques intervient dans le cycle de vie d’un projet génomique dès la conception du projet et jusqu'à la valorisation des résultats. En amont, il est souhaitable de disposer d’une expertise en bioinformatique afin de pouvoir dimensionner correctement le projet (sur les plans techniques, scientifiques et organisationnels). Une fois en possession de données génomiques à analyser, il faut pouvoir les stocker et les référencer, idéalement dans une démarche F.A.I.R, afin de les rendre disponibles pour tous les intervenants du projet. Les données brutes, sous formes de fichiers FASTQ, sont alors transformées en fichiers d’analyse primaire (tables de comptage pour du RNASeq, fichiers de variants, …). Cette transformation est réalisée par des chaînes de traitement (pipelines) qui nécessitent généralement une infrastructure robuste (cluster de calcul, disque capacitifs et disques performants en I/O, bande passante adaptée) et des compétences en bioinformatiques solides. Les fichiers issus de l’analyse primaire sont ensuite exploités afin de répondre à la question scientifique à l’origine du projet. Cette étape nécessite des compétences de bioinformaticien/ biostatisticien / data scientists. Enfin, une fois les résultats produits, il convient de les valoriser en proposant des représentations pertinentes (tableaux/graphiques) pour des publications scientifiques, et en soumettant éventuellement les jeux de données sur des sites adaptés
offre de service moabi